Data Tables¶
As a project develops and scales, you’ll soon find that it demands data organization beyond the use of simple variables, and beyond tools like folders, labels, and trigger libraries. For organizing large volumes of data, the Editor offers a pair of higher level data structures.
One such structure is the Array. This element is explained in more detail elsewhere in the manual, but as a refresher it’s worth noting that any variable in the Editor may be transformed into an array. This will expand the variable beyond a single value into an array sized for any number of variables of a certain type, provided the size and type are defined in the Trigger Editor prior to play.
Arrays have great utility, they are strongly typed and readily accessed. They are a mainstay of creating things with the Editor. Still, their construction is rigid. They can be made quickly, but must be well designed, since you can’t change their structure during game time. For scenarios that require something more flexible, you can use the other higher level data structure, the Data Table.
As their name implies, data tables order data into a table stored in the backend of a map. While you can’t physically see this table, it takes the following abstract form.
| Name | Value |
|---|---|
| Name | Value |
| Name | Value |
| Name | Value |
| … | … |
As shown above, a data table hosts data that has been entered into the table as a name-value pair. The Name classifies the data under a unique string that is set when the data is written to the table. This string serves as a handle for finding the data again, whether retrieving it for use or removing it from the table. The Value is the value of the table entry, just the same as a single variable has a value or an array component has a value. In addition to this, each entry has its own implicit Type; the type of data is set based on which trigger action is used to write the data to the table.
Data Table Properties¶
In contrast to arrays, the structure of data tables is not rigidly defined before game time. They may grow or shrink in size, having entries appended or removed during gameplay. Moreover, the data table itself has no type, it can contain any mixture of data types, the composition of which can be in constant flux.
Data tables possess these properties because they do not consume a fixed, constant amount of memory, instead using something called Dynamic Memory Allocation. Under dynamic memory allocation, memory is declared and used by the table, then released when it is no longer needed. Fortunately, using the Editor means you don’t really need to know the specifics of memory use. All you need to take away from this is that data tables are dynamic, while arrays are static.
Another difference between data tables and arrays is the impact they have on performance. Since these structures operate as containers, you may already have realized that locating their contents will take the engine some amount of time. Not only is this correct, but it is a definable property. Every time a value from one these structures is used, there is a Search Time that describes how long it takes the Editor to find something in one of these containers as a product of how many things are in the container. Arrays have Linear Search Time. Every component added will linearly increase the search time. Making an array 10 times bigger, will increase the search time by 10 times too. By virtue of their name-value pairing, Data tables have Constant Search Time. Strange as it may sound, making a data table 10 times bigger will not affect its search time.
If this topic feels like an unwelcome glimpse into the back-end of the Editor, take heart. The important thing here is that you learn that data tables perform much better for ‘large’ collections of data. The exact definition of ‘large’ here depends on the specific project at hand, and for most ‘small’ amounts of data both structures will provide adequate results. As a rule of thumb for those with little experience, it is best to consider the other advantageous properties of a data structure well in advance of performance considerations. If you start seeing performance slippage in a game, adapting ‘large’ arrays into data tables is a clear way to seek improvements.
As a last note, there is one drawback to dynamic memory allocation in the possibility of a Memory Leak. This occurs when memory is being allocated, but not being freed after use. Just as a leak in a boat will cause it to slowly take on water, a leaking data table will result in a project consuming more and more memory over time. This will cause the game to start to sink, slowing down or even crashing once no more memory resources are left to use. Keep in mind that data tables give more control during game time than arrays, but in more complex projects they can require some tidying up.
Data Table Actions¶
Data tables are constructed, used, and destroyed using of a set of trigger actions. These actions can be found during action creation by navigating to the ‘Data Table’ label, as shown below.
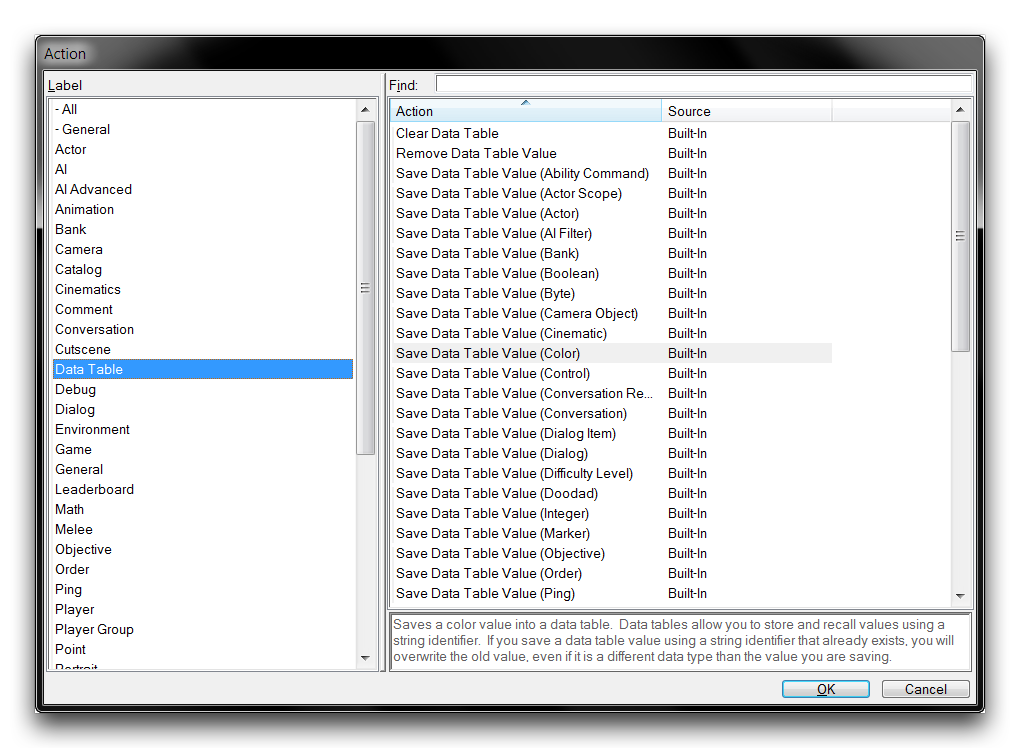 Data Table Actions
Data Table Actions
Despite the length of this list, there are only three major actions. The length is due to one of the actions being made available in many versions. The actions are broken down in the table below.
| Action | Effect |
|---|---|
| Clear Data Table | Clears a data table, removing all of its entries. The data table is selected by specifying the Scope it is found in. |
| Remove Data Table Value | Removes a specific entry from a data table. The entry is selected by using its Name, and the Scope of the data table it is stored in. |
| Save Data Table Value | Adds an entry to a data table. The entry is written to the table by specifying its Name and Value pair, then selecting the Scope of the data table being written to. Almost every Editor data type has its own version of this action; there are 46 versions in total. Depending on the selected version, the data’s Type is implicitly set within the table. |
Data Table Scope¶
Every data table exists at a certain scope, either Global or Local. These scopes are used to target specific data tables for reading or writing data. Below is an example action, which writes the Point ‘Unit Spawn’ to the Global data table.
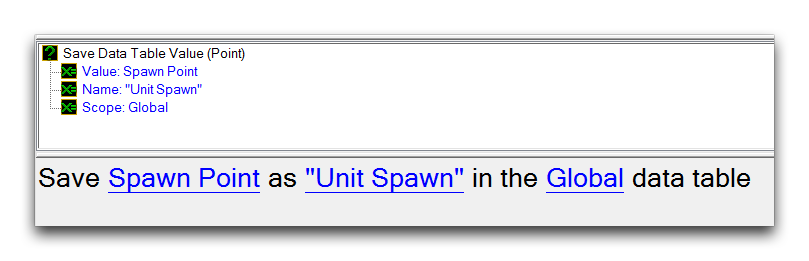 Writing Data to the Global Data Table
Writing Data to the Global Data Table
The Global data table has universal access, is singular, and always exists within a project. By contrast, Local data tables have their access tied to a single trigger. A Local data table is created once data is first written within a trigger using a Save Data Table Value action. The table will then receive any further data that is written at its scope until it is cleared. Similarly to Local variables, Local data tables are also cleared when their hosting trigger has concluded.
As a result of data table scope, there are pseudo-limits on a user’s ability to create and target data tables. At any location within a project’s logic, only the Global table or the current trigger’s Local table may be used directly. Values can be passed between triggers to access other Local scopes, which may be a key consideration in the program’s design.
The major advantage of scope is in insulating a project from memory leaks. Since Local scopes are eliminated after a trigger finishes, there is an automatic failsafe for removing or clearing data in Local data tables. The corollary to this, is that the Global data table is the main culprit for memory leaks, and you should watch it carefully if it’s being used frequently in a project.
VALUE FROM DATA TABLE FUNCTIONS -------------------------------
Data is retrieved from data tables using a set of versioned Value From Data Table functions. You can access these during any field-filling by navigating to the ‘Function’ source and sorting by the ‘Data Table’ label, as shown below.
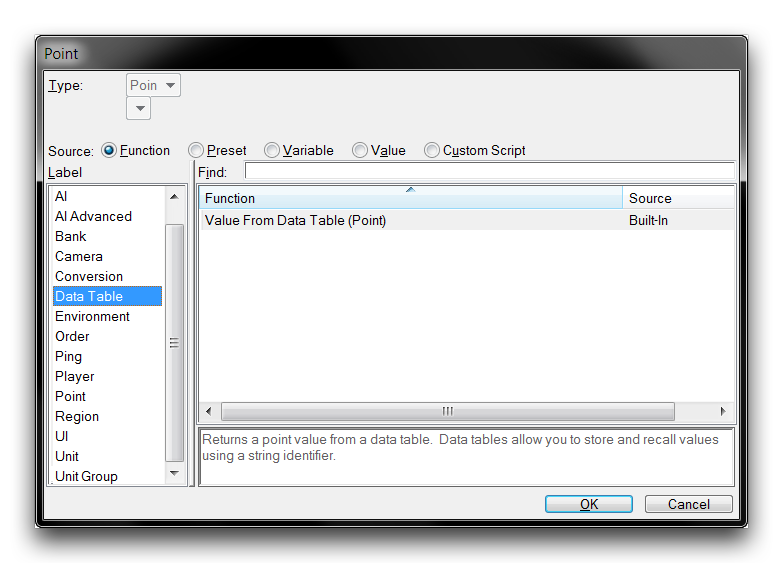 Value From Data Table Function for Points Data
Value From Data Table Function for Points Data
The above example shows the Value From Data Table function available for Points. This function is demonstrated in the following example.
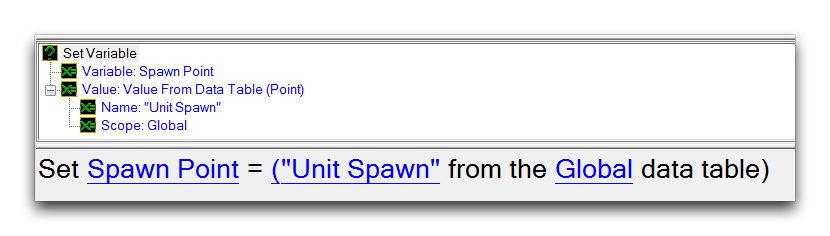 Reading Points Data from the Global Data Table
Reading Points Data from the Global Data Table
Here, a Point has been retrieved from the Global data table, using its Name ‘Unit Spawn.’ It has then been set to a variable for further use.